未标记样本
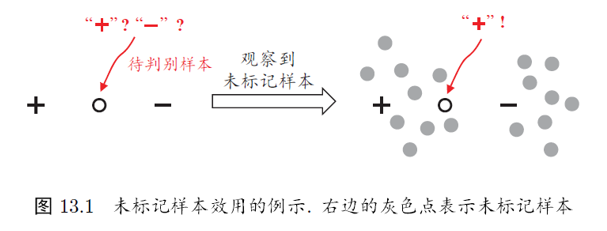
要利用未标记样本,必然需要做一些假设,将未标记样本所揭示的数据分布信息和类别标记相联系。有两种常见的假设
- 聚类假设(clustering assumption):假设数据存在簇结构,同一簇的样本属于同一类别
- 流形假设(manifold assumption):假设数据分布在一个流形结构上,邻近的样本具有相似的输出值
流形假设可以看作聚类假设的推广
生成式方法
假设样本由高斯混合模型生成,且每个类别对应一个高斯混合成分:
\[p(x)=\sum\limits_{i=1}^k\alpha_i\cdot p(x\vert\mu_i,\Sigma_i) \\ p(x\vert\mu_i,\Sigma_i)=\frac{1}{(2\pi)^{n/2}\vert\Sigma_i\vert^{frac{1}{2}}} e^{-\frac{1}{2}(x-\mu_i)^T\Sigma_i^{-1}(x-\mu_i)}\]最大化后验概率可知
\[\begin{aligned} f(x)&=\mathop{\arg\max}\limits_{j\in\mathcal{y}}p(y=j\vert x)\\ &=\mathop{\arg\max}\limits_{j\in\mathcal{y}}\sum\limits_{i=1}^k p(y=j,\Theta=i\vert x)\\ &=\mathop{\arg\max}\limits_{j\in\mathcal{y}}\sum\limits_{i=1}^k p(y=j\vert\Theta=i, x)\cdot p(\Theta=i\vert x) \end{aligned}\\ p(\Theta=i\vert x)=\frac{\alpha_i p(x\vert \mu_i,\Sigma_i)}{\sum_{i=1}^k\alpha_i p(x\vert \mu_i,\Sigma_i)}\]假设样本独立同分布,且由同一个高斯混合模型生成,则对数似然函数为
\[\begin{aligned} \ln p(D_l\cup D_u)&=\sum\limits_{(x_i,y_j)\in D_l} \ln (\sum\limits_{i=1}^k\alpha_i\cdot p(x_j\vert u_i,\Sigma_i)\cdot p(y_j\vert\Theta=i,x_j))\\ &+\sum\limits_{x_i\in D_u} \ln (\sum\limits_{i=1}^k\alpha_i\cdot p(x_j\vert u_i,\Sigma_i)) \end{aligned}\]高斯混合的参数估计可以采用EM算法求解,迭代更新式如下:
- E步:根据当前模型参数计算未标记样本属于各个高斯混合成分的概率
- M步:基于 $\gamma_{ji}$ 更新模型参数
将上述过程中的高斯混合模型换成混合专家模型、朴素贝叶斯模型就可以推导出其他生成式半监督算法
此类方法简单、易于实现,在有标记数据极少的情形下往往比其他方法性能更好
然而此类方法有一个关键:模型假设必须准确,否则利用未标记数据反而会显著降低泛化性能
半监督SVM
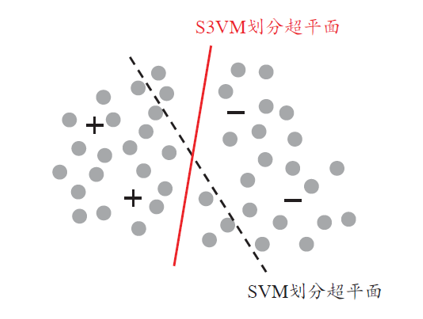
半监督支持向量机中最著名的是 TSVM(Transductive SVM)
\[\min\limits_{w,b,\hat{y},\xi}\frac{1}{2}\Vert w\Vert_2^2 +C_l\sum\limits_{i=1}^l\xi_i+C_u\sum\limits_{i=l+1}^m\xi_i\\ \begin{aligned} s.t. &\quad y_i(w^Tx_i+b)\ge 1-\xi_i \quad,i=1,\dots,l\\ & \quad\hat{y_i}(x^Tx_i+b)\ge 1-\xi_i \quad,i=l+1,\dots,m\\ & \quad\xi_i\ge 0 \quad,i=1,\dots,m \end{aligned}\]TSVM 采用局部搜索来迭代寻找近似解
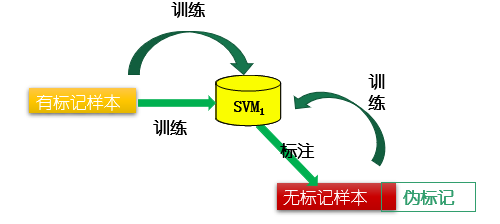
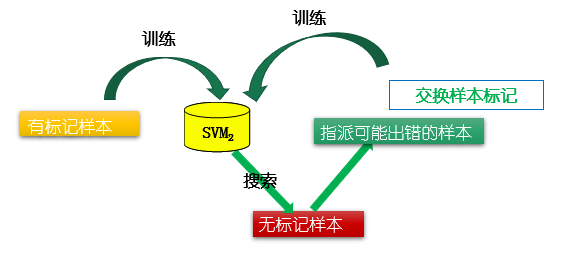

未标记样本进行标记指派和调整的过程中,有可能出出现 类别不平衡问题
为了减轻类别不平衡所造成的不利影响,可以对算法进行稍加改进:将优化目标中的 $C_u$ 拆分称 $C_u^+,C_u^-$ 两项,并在初始化时令:
\[C_u^+=\frac{u_-}{u_+}C_u^-\]显然,搜索标记指派可能出错的每一对未标记样本进行调整,仍然是一个涉及 巨大计算开销 的大规模优化问题
因此,半监督SVM研究的一个重点是如何 设计出高效的优化求解策略 ,例如基于图核(graph kernel)函数梯度下降的Laplacian SVM、基于标记均值估计的meansSVM等
图半监督学习
给定一个数据集,我们可以将其映射成一个图,数据集中每个样本对应图中的一个节点,若两个样本之间的 相似度很高(或相关性很强) ,则对应的节点之间存在一条边,边的强度(strength)正比于样本之间的相似度
我们可以将有标记样本所对应的节点作为染色节点,未标记样本作为未染色节点。于是,半监督学习就对应于”颜色“在图上扩散或传播的过程
由于一个图对应了一个矩阵,这就使得我们能基于矩阵运算来进行半监督学习算法的推导和分析
二分类问题
我们先基于 $D_t\cup D_u$ 构建一个图 $G=(V,E)$ ,其中节点集合
\[V={x_1,\dots,x_l,x_{l+1},\dots,x_{l+u}}\]边集合表示为一个亲和矩阵(affinity matrix),常基于高斯函数定义:
\[W_{i,j}= \left\{ \begin{aligned} exp(-\frac{\Vert x_i-x_j\Vert_2^2}{2\sigma^2}) & \quad\text{if}\quad i\ne j\\ 0 & \quad\text{otherwise} \end{aligned} \right.\]假定从图G中学得一个实值函数 $f:V\rightarrow\mathbb{R}$
直观上讲相似的样本应该具有相似的标记,即得到最优结果。于是可以定义关于 f 的能量函数(energy function):
\[\begin{aligned} E(f)&=\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m W_{ij}(f(x_i)-f(x_j))^2\\ &=\frac{1}{2}(\sum\limits_{i=1}^m d_i f^2(x_i) +\sum\limits_{j=1}^m d_j f^2(x_j)-2\sum\limits_{i=1}^m\sum\limits_{j=1}^m W_{ij}f(x_i)f(x_j))\\ &=f^T(D-W)f \end{aligned}\]采用分块矩阵标识方法:
\[\begin{aligned} E(f)&=(f_l^T f_u^T)( \begin{bmatrix} D_{ll} & 0_{lu}\\ 0_{ul} & D_{uu} \end{bmatrix}- \begin{bmatrix} W_{ll} & W_{lu}\\ W_{ul} & W_{uu} \end{bmatrix} ) \begin{bmatrix}f_l\\ f_u\end{bmatrix}\\ &=f_l^T(D_{ll}-W_{ll})f_l+f_u^T(D_{uu}-W_{uu})f_u -2f_u^TW_{ul}f_l \end{aligned}\]由 $\frac{\partial E(f)}{\partial f(u)}=0$ 可得:
\[f_{u}=(D_{uu}-W_{uu})^{-1}W_{ul}f_l\]设矩阵P
\[P=D^{-1}W= \begin{bmatrix} D_{ll}^{-1}& 0_{lu}\\ 0_{ul}^{-1}& D_{uu}^{-1} \end{bmatrix} \begin{bmatrix} W_{ll}& W_{lu}\\ W_{ul}& W_{uu} \end{bmatrix}= \begin{bmatrix} D_{ll}^{-1}W_{ll}& D_{ll}^{-1}W_{lu}\\ D_{uu}^{-1}W_{ul}& D_{uu}^{-1}W_{uu} \end{bmatrix}\\ P_{uu}=D_{uu}^{-1}W_{uu}\\ P_{ul}=D_{uu}^{-1}W_{ul}\\\]可得
\[\begin{aligned} f_u &=(D_{uu}(I-D_{uu}^{-1}W_{uu}))^{-1}W_{ul}f_l\\ &=(I-D_{uu}^{-1}W_{uu})^{-1}D_{uu}^{-1}W_{ul}f_l\\ &=(I-P_{uu})^{-1}P_{ul}f_l \end{aligned}\]多分类问题
上面描述了一个针对二分类问题的”单步式“标记传播(label propagation)方法,下面提出适用于多分类问题的”迭代式“标记传播方法
仍然基于节点集合构建一个图,定义一个 $(l+u)\times\vert\mathcal{Y}\vert$ 的非负标记矩阵 $F=(F_{1}^T,\dots,F_{\vert\mathcal{Y}\vert}^T)^T$ ,其第i行元素 $F_i=(F_{i,1},\dots,F_{i,\vert\mathcal{Y}\vert})$ 为示例 $x_i$ 的标记向量,相应的分类规则为:
$y_i=\mathop{\arg\max}{1\le j\le\vert\gamma\vert}F{ij}$
将F初始化为:
\[F(0)=Y_{ij}=\left\{ \begin{aligned} &1\text{ , if }(1\le i\le l)\land (y_i=j)\\ &0\text{ , otherwise} \end{aligned} \right.\]基于W构造一个标记传播矩阵 $S=D^{-\frac{1}{2}}WD^{-\frac{1}{2}}$ ,其中
\[D^{-\frac{1}{2}}=(\frac{1}{\sqrt{d_l}},\cdots,\frac{1}{\sqrt{d_l+u}})\]于是有迭代计算式:
\[F(t+1)=\alpha SF(t)+(1-\alpha)Y\]基于迭代至收敛可得:
\[F^*=\lim\limits_{t\rightarrow\infty}F(t)=(1-\alpha)(I-\alpha S)^{-1}Y\]
图半监督学习方法在概念上相当清晰,且易于通过矩阵运算分析来探索算法性质。
但此类算法的缺陷在于:
- 存储开销高
- 构图过程仅能考虑训练样本集,难以判断新样本在图中的位置,所以在接收新样本时,需要对图进行重构
基于分歧的方法
基于分歧的方法(disagreement-based methods)使用多学习器,而学习器之间的分歧(diversity)对未标记数据的利用非常重要
协同训练(co-training)是基于分歧的方法的重要代表,最初是针对”多视图“(multi-view)数据设计的
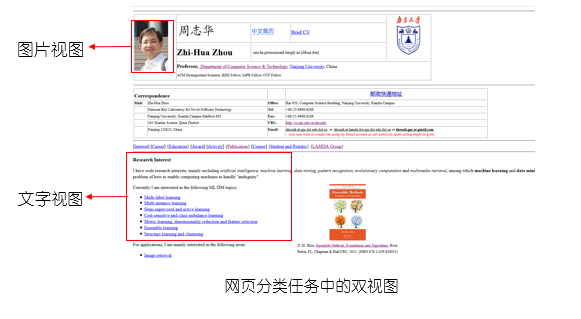
协同训练利用了多视图之间的”相容互补性“,假设数据拥有两个”充分“(sufficient)且”条件独立“的视图
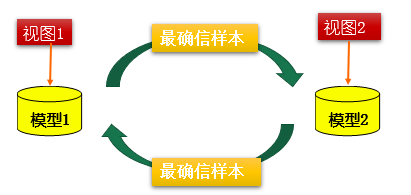

协同训练过程虽然简单,但是理论证明显示,如果两个视图”充分且条件独立“,则可以利用未标记样本通过协同训练将弱分类器的泛化性能提升到任意高
虽然实际中视图的条件独立性很难满足,但是在更弱的条件下,协同训练仍可以有效提升弱分类器的性能
基于分歧的方法只要采用合适的基学习器,就较少受到模型假设、损失函数非凸性和数据规模问题的影响,学习方法简单有效、理论基础相对坚实。
半监督聚类
聚类是典型的无监督学习任务,但是现实聚类任务往往能得到一些额外的监督信息,可以通过半监督聚类(semi-supervised clustering)来获得更好的聚类效果
聚类任务中的监督信息大致有两种类型:
- 第一种是”必连“(must-link)与”勿连“(cannot-link)约束,前者指样本必属于同一个簇,后者则是样本必不属于同一个簇
- 第二种类型的监督信息是少量的有标记样本
约束k均值
约束k均值(constrained k-means)算法利用了第一类监督信息,基于kmeans算法,在聚类的过程中,确保满足”必连“关系集合和”勿连“关系集合中的约束,否则返回错误提示

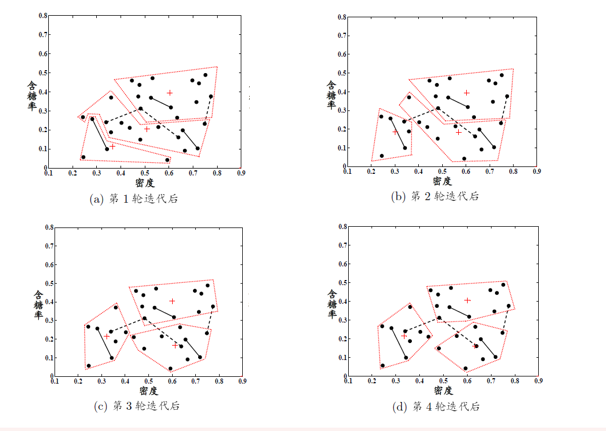
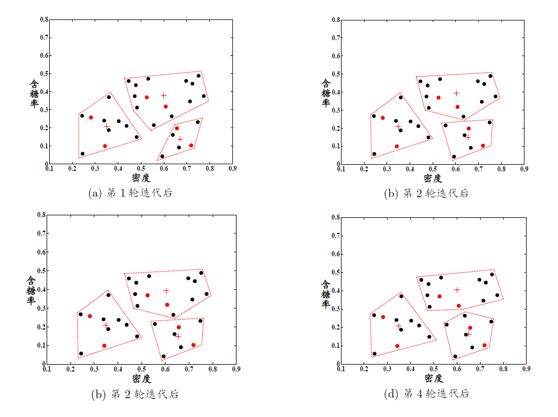
约束种子k均值
约束种子k均值(constrained seed k-means)算法利用了第二类监督信息,即假设少量有标记样本属于k个聚类簇
对于监督信息,直接将它们作为”种子“,初始化kmeans算法的k个聚类中心,并在聚类簇迭代更新的过程中不改变种子样本的簇隶属关系。

总结
半监督学习利用未标记样本后并非必然提升泛化性能
- 对生成式方法,可能是模型假设不准确,需要依赖充分可靠的领域知识来设计模型
- 对半监督SVM,可能是训练数据中存在多个”低密度划分“
半监督学习的四大范型(paradim):生成式方法、图版监督学习、基于分歧的方法、半监督SVM