特征选择
特征:描述物体的属性
特征的分类:
- 相关特征
- 无关特征
- 冗余特征:包含的信息能从其他特征推演出来
特征选择:从给定的特征集合中选出任务相关的特征子集,保证不丢失重要特征
原因:
- 减轻维度灾难:少量特征构建模型
- 降低学习难度:留下关键信息
特征选择的可行方法:
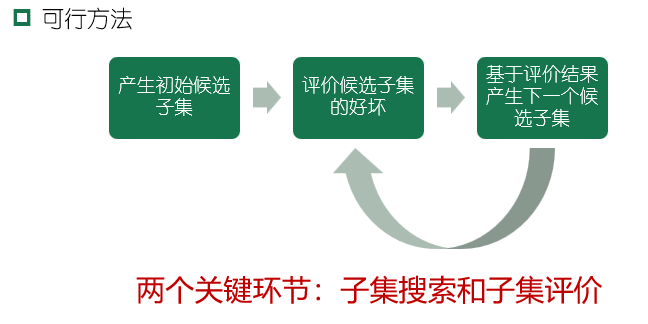
子集搜索
用贪心策略选择包含重要信息的特征子集:
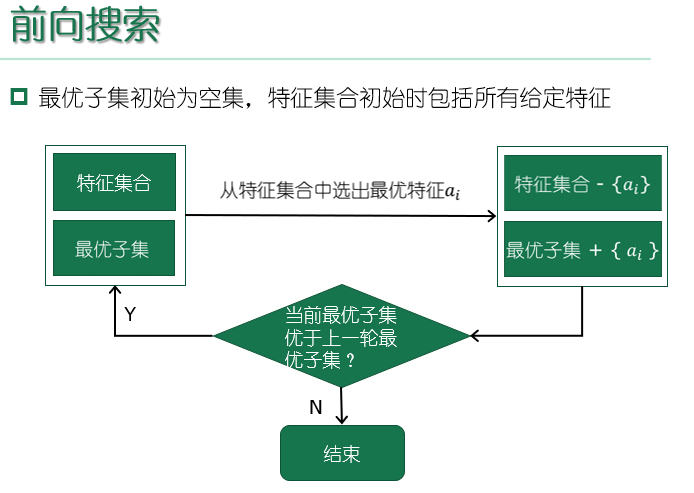
- 前向搜索:逐渐增加相关特征
- 后向搜索:从完整的特征集合开始,逐渐减少特征
- 双向搜索:每一轮逐渐增加相关特征,同时减少无关特征
子集评价
- 特征子集对数据集进行划分
- 每个划分区域对应特征子集的某种取值
- 样本标记对数据集进行真实划分
通过估算这两个划分的差异,来对特征子集进行评价;与样本标记对应的划分差异越小,说明当前特征子集越好
用信息熵进行子集评价:
- 特征子集A确定了对数据集D的一种划分
- 在A的取值上将D分为V份,每一份表示为 $D^v$
- $Ent(D^v)$ 表示 $D^v$ 上的信息熵
- 样本标记Y对应的数据集D的真实划分
- $Ent(D^v)$ 表示 $D$ 上的信息熵
- 计算信息增益
将特征子集搜索机制和子集评价机制相结合,得到常用的三种特征选择方法:过滤式、包裹式、嵌入式
过滤式选择
先用特征选择过滤原始数据,再用过滤后的特征来训练模型;特征选择过程和后续学习器无关
Relief(Relevant Feature)方法:
- 为每个初始特征赋予一个”关统计量,度量特征的重要性
- 特征子集的重要性由子集的中每个特征所对应的相关统计量之和决定
- 设计一个阈值,然后选择比阈值大的相关统计量分量所对应的特征
- 指定欲选取的特征个数,然后选择相关统计量分量最大的指定个数特征
相关统计量的确定:
- 猜中近邻(near-hit): $x_i$ 的同类样本中的最近邻 $x_{i,nh}$
- 猜错近邻(near-miss): $x_i$ 的异类样本中的最近邻 $x_{i,nm}$
相关统计量对应属性j的分量为
\[\delta^j=\sum\limits_{i}-diff(x_i^j,x_{i,nh}^j)^2+diff(x_i^j,x_{i,nm}^j)^2\]若j为离散型,则 $x_a^j=x_b^j$ 时, $diff(x_a^j,x_b^j)=0$ ,否则为1;
若j为连续型,则 $diff(x_a^j,x_b^j)=\vert x_a^j-x_b^j\vert$
属性j上的相关统计量越大,猜对近邻越近,猜错近邻越远,属性j对区分对错越有用
Relief方法的时间开销随着采样次数以及原始特征线性增长,运行效率很高
Relief的扩展方法Relief-F处理多分类问题
\[\delta^j=\sum\limits_{i}-diff(x_i^j,x_{i,nh}^j)^2+\sum\limits_{l\ne k}(p_l\times diff(x_i^j,x_{i,nm}^j)^2)\]其中 $p_l$ 为第l类样本在D中的分布比例
包裹式选择
包裹式选择直接把最终将要使用的学习器的性能作为特征子集的评价准则
- 包裹式特征选择的目的就是找到为学习器量身定做的特征子集
- 需要多次训练学习器,开销通常比过滤式大
LVW(LasVegas Wrapper)在拉斯维加斯方法框架下使用随机策略来进行子集搜索,并以最终分类器的误差作为特征子集的评价准则
嵌入式选择
嵌入式特征选择将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,学习器在训练的过程中自动进行特征选择
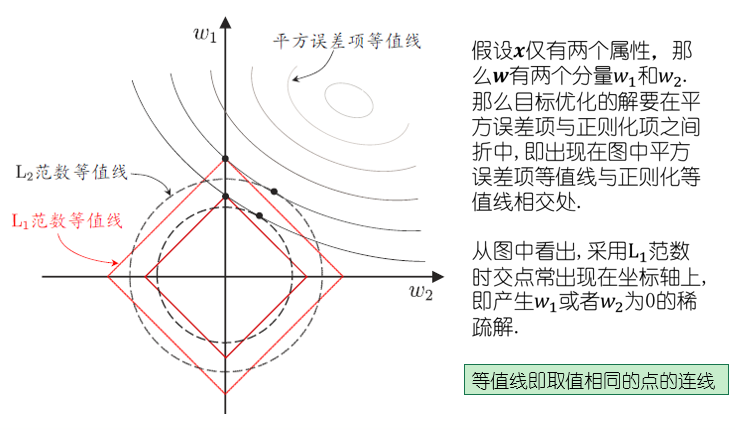
比如最简单的线性回归模型,以平方误差为损失函数,并引入L2正则化防止过拟合(岭回归):
\[\min\limits_{w}\sum\limits_{i=1}^m(y_i-w^Tx_i)^2+\lambda\Vert w\Vert_2^2\]如果将L2范数替换为L1范数,则有LASSO:容易获得稀疏解,是一种嵌入式特征选择的方法
稀疏表示
将数据集表示成一个矩阵,每行对应一个样本,每列对应一个特征;矩阵中有很多零元素,且并非整行整列出现
稀疏表达的优势:
- 文本数据线性可分
- 存储高效
稀疏表示:将稠密表示的数据集转化为”稀疏表示“,使其享受稀疏表达的优势
字典学习
字典学习:为普通稠密表达的样本找到合适的字典,将样本转化为稀疏表示的过程
给定数据集 ${x_1,\dots,x_m},x_i\in\mathbb{R}^{n\times k}$
学习目标是字典矩阵 $B\in\mathbb{R}^{d\times k}$ 以及样本的稀疏表示 $\alpha_i\in\mathbb{R}^k$
k称为字典的词汇量,由用户指定
则最简单的字典学习的优化形式为
\[\min\limits_{B,\alpha_i}\sum\limits_{i=1}^m\Vert x_i-B\alpha_i\Vert_2^2+\lambda\sum\limits_{i=1}^m\Vert\alpha_i\Vert_1\]压缩感知
能否利用部分数据恢复全部数据?
压缩感知(compressive sensing):
长度为m的离散信号x,用远小于奈奎斯特采样定理要求的采样率,采样得到长度为n的采样后信号y, $n\ll m$
一般不能用y还原x,但是若存在某个线性变换 $\Psi$ ,使得 $x=\Psi s$ ,其中s是稀疏向量
比如傅里叶变换、余弦变换、小波变换
A具有限定等距性时,可以几乎完美地恢复s
限定等距性(restricted isometry property,即RIP):
$A\in\mathbb{R}^{n\times m}$ ,若存在常数 $\delta_k\in(0,1)$ 使得对于任意向量s和A的所有子矩阵 $A_k\in\mathbb{R}^{n\times m}$ 有
则称A满足k-限定等距性(k-RIP)
矩阵补全