结构化查询语言
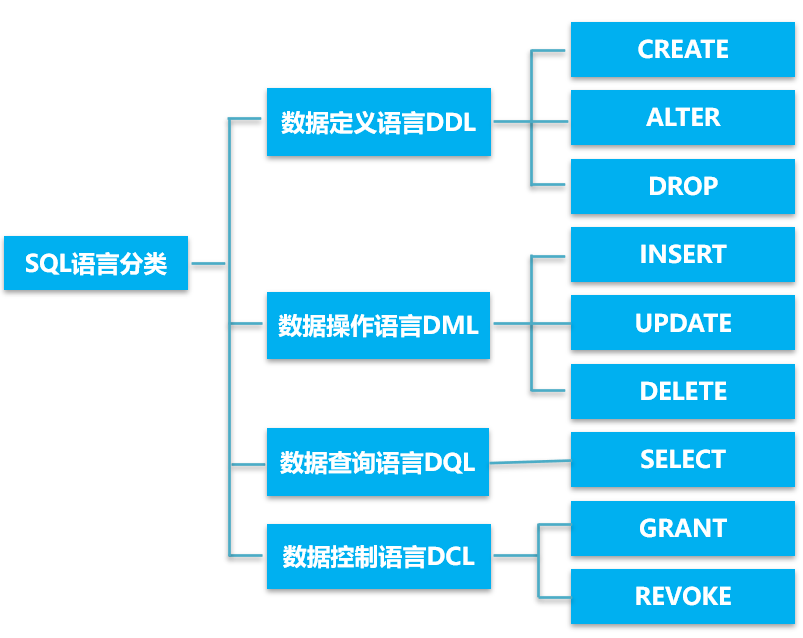
数据定义语言DDL
create
Create操作包括定义数据库,定义表
datebase/schema/table/view/index
- 创建一个仅有数据库名的数据库
CREATE DATABASE Teach
- 创建表
CREATE TABLE
CREATE TABLE School (
SchoolID char(3) primary key, --学院ID
SchoolName varchar(50) not null) --学院名称
约束
约束可以定义字列上或者是表上,可以在创建表的时候定义也可以创建之后修改约束定义。
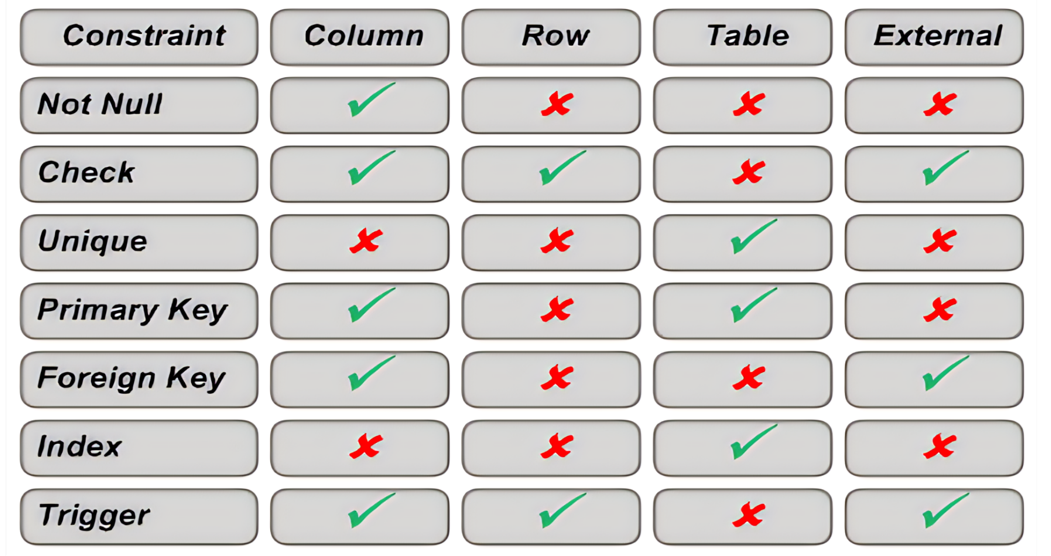
定义约束:
约束条件命名规则
column [CONSTRAINT constraint_name] constraint_type,
其中column是列的名字,CONSTRANIN是添加约束的关键词,后面跟着你自己给约束起的名字,然后指明约束类型
下面给出一些具体的例子:
deptno NUMBER(7,2) NOT NULL); --not null约束
CONSTRAINT dept_dname_uk UNIQUE(dname)) --unique key约束
CONSTRAINT dept_deptno_pk PRIMARY KEY(deptno)) --主键约束
CONSTRAINT emp_deptno_fk FOREIGN KEY (deptno)
REFERENCES dept (deptno)) --外键约束
CONSTRAINT emp_deptno_ck
CHECK (DEPTNO BETWEEN 10 AND 99) --check约束
要注意是否会漏掉主键外键的定义:
首先先分析给出的表的关系,连接得到的表一定存在外键,主键也可能是外键,不能漏掉
根据ER图定义表的时候,有些属性应该是联系里面的,加到实体中后会导致实体完整性受影响
Alter
修改表的定义和索引:ALTER TABLE
alter table/view/index add/modify/alter/drop
ALTER TABLE table_name
ADD (column datatype [DEFAULT expr] --增加一列
[, column datatype]...)
为列增加约束条件,但受到表中已有数据的限制
ALTER TABLE table_name --修改某一列
MODIFY/Alter (column datatype [DEFAULT expr]
[, column datatype]...)
对默认值的变更只影响后续插入表的数据
ALTER TABLE table_name --删除某一列
DROP (column...)
alter table student add unique(sname) --增加表约束
ALTER TABLE Student DROP UNIQUE(Sname) --删除表约束
DROP
删除表:DROP TABLE
DROP TABLE student
所有的数据及结构均被删除 任何未决的事务被提交 所有索引被删除 你不能 roll back 这个操作
索引
加快查询速度、保证行的唯一性,一般是在主键以及unique上面建立索引。
- 建立索引
create [unique][clustered] index <索引名>
on <表名>(<列名>[<次序>][,<列名>[<次序>]]…)
CREATE INDEX emp_ename_idx
ON emp(ename)
- 索引类型
- unique:唯一性索引,不允许表中不同的行在索引列上取相同的值。
- clustered:聚簇索引,表中元组按照索引项的值排序并物理地聚簇在一起。一个表上只能建立一个聚簇索引
- acs/desc:索引地排序次序
- 删除索引
DROP INDEX index-name
维护索引
DBMS自动完成
使用索引
DBMS自动选择是否使用索引以及使用哪些索引
可以动态地定义索引,即可以随时建立和删除索引
数据的物理独立性
查询范围大、查询数量少使用索引
数据操作语言
INSERT
插入一行记录:
INSERT INTO dept (deptno, dname, loc)
VALUES ('50', 'DEVELOPMENT', 'DETROIT')
在列中可以忽略为空地列,也可以插入函数值。给出的列和值地信息必须一一对应,如果没有指定列,values地值必须和数据表结构地定义一致,包括顺序,类型,字段数等。
插入子查询数据
insert into CS_student
select sno,sname
from Student where schoolID='480'
执行插入语句的时候系统会检查完整性约束,判断是否能插入。
insert into values/子查询语句
插入带空值的行:列中忽略空的列
插入函数值
UPDATE
UPDATE table
SET column = value [, column = value]
[WHERE condition]
用wehere明确定义要修改的行
UPDATE emp
SET deptno = 20
WHERE empno = 7782
用子查询来更新:
UPDATE emp
SET (job, deptno) =
(SELECT job, deptno
FROM emp
WHERE empno = 7499)
WHERE empno = 7698
update set 列=value/子查询语句 where 条件
DELETE
DELETE [FROM] table [WHERE condition]
用where来明确指明要删除的行
DELETE FROM dept
WHERE dname = 'DEVELOPMENT’
用子查询来判定要删除的行
DELETE FROM emp
WHERE deptno =
(SELECT deptno
FROM dept
WHERE dname ='SALES')
不能违反约束:不能删除正在被外键引用的行。
数据查询语言DQL
select语法:获取列在SELECT语句中用DISTINCT消除重复行
SELECT [DISTINCT] {*, column [alias],...}
FROM table
需要注意的是:NULL不等于0,对NULL值的运算结果还是NULL值。NULL不参与运算
distinct消除重复行放在聚集函数里面,count(distinct sno)
not
起别名:在列名和别名之间可采用AS关键字进行标识
SELECT ename AS name, sal salary
FROM emp
连接符号:用连接符号“+”能创建一个列为组合字符串表达式
SELECT ename+ job AS 'Employees'
FROM emp
where
where语句获取满足条件的行。哦那个在from后面
运算符
between:获取一个范围的结果
SELECT ename, sal
FROM emp
WHERE sal BETWEEN 1000 AND 1500
in:判断枚举数据中的存在性
SELECT empno, ename, sal, mgr
FROM emp
WHERE mgr IN (7902, 7566, 7788)
like:用like操作符从一个字符串中进行匹配查询。%表示0到多个字符匹配,_表示单个字符匹配。
SELECT ename
FROM emp
WHERE ename LIKE ‘%on'
如果想要搜索本身就带%之类特殊字符的内容,可以用转义符‘\’。
IS NULL:判断是不是空值
SELECT ename, mgr
FROM emp
WHERE mgr IS NULL
使用谓词 IS NULL 或 IS NOT NULL “IS NULL” 不能用 “= NULL” 代替
逻辑操作符:AND OR NOT
结果排序:ORDER BY
**ASC:升序(默认)DESC:降序 limit k只显示前k个结果 **
SELECT ename, job, deptno, hiredate
FROM emp
ORDER BY hiredate DESC
JOIN连接
用连接从多个表中查找数据。JOIN连接条件在WHERE语句中,相同的列名在多个表中出现的时候,需要加表明来加以区分。
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column1 = table2.column2
这一种是不用JOIN关键词,连接条件就放在where中表示。
连接的类型
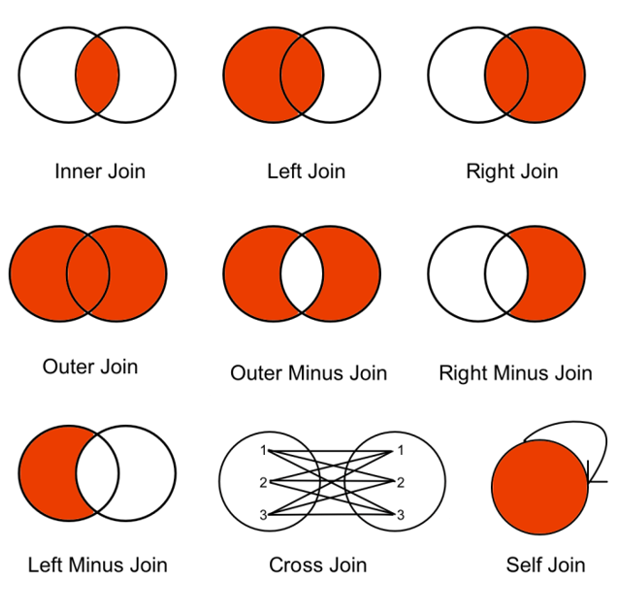
内连接
-
对等连接:就是JOIN连接。
-
非对等连接:
SELECT e.ename, e.sal, s.grade
FROM emp e, salgrade s
WHERE e.sal
BETWEEN s.losal AND s.hisal
其实就是判断条件不一样而已,对等就是相等的连接,非对等就是按照给定的条件连接。
外连接
用外部连接可以获取不满足连接条件的行
SELECT table1.column, table2.column
FROM table1 LEFT OUTER JOIN table2
ON table1.column = table2.column
用了JOIN关键字,连接条件就用ON来表示。
内连接(对等和非对等都是使用from,外连接from+on)
连接是可以自身连接的,要给表起个别名来标识。
分组函数:
- AVG、SUM
- MIN、MAX
- COUNT
GROUP BY
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column]
有了GROUP BY 语句就是表中的数据按照指定的列进行分组,所以说select中出现的列一定要在GROUP BY 语句中出现才行。但是GROUP BY 语句中的列不一定出现在SELECT 中。
要么出现在group by要么出现在聚合函数中
HAVING语句
用HAVING限制组的输出,相当于where的作用。having是用在group by里面的。
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column]
子查询
SELECT select_list
FROM table
WHERE expr operator
(SELECT select_list
FROM table)
将子查询放在()里面,放在比较运算符的右边,熊在子查询中增加order by语句
用单行操作符和单行子查询进行运算:=,>=等
用多行操作符与多行子查询进行运算。:IN、ANY、ALL等
<ANY等价于<MAX()
<ALL等价于<MIN()
EXISTS条件查询
指定一个子查询,检测行的存在,如果子查询包含行,则返回TRUE。
--查找与出版商住在同一城市中的作者
SELECT au_lname, au_fname
FROM authors
WHERE exists
(SELECT 1 FROM publishers
WHERE authors.city = publishers.city)
如果子查询存在,则返回true
视图
创建视图
CREATE VIEW viewname
[(alias[, alias]...)]
AS subquery
举例子:
-- 创建部门编号为10的职工信息视图
CREATE VIEW empvu10
AS SELECT empno, ename, job
FROM emp
WHERE deptno = 10
create view vname as 子查询语句
子查询语句不能有order by–取决于数据库配置
视图行的操作规则
在简单视图上可以进行DML操作。会改变基本表
有GROUP函数、GROUP BY语句、DISTINCT关键字的时候不能更新数据。表达式定义的列、嵌套查询也不能使用DML
删除视图
删除视图并不会丢失数据,从该视图导出的其他视图定义仍然在数据字典中,必须显式删除。
视图的作用
- 提供逻辑独立性:假设现在原来的一个表被拆分成了两个表,但是可以通过建立一个视图,将两个表连接起来,让用户模式并保持不变。
- 提供机密数据的安全保护:对不同用户定义不同视图,让每个用户只有权看到他有权看到的数据。
数据控制语言DCL
数据控制功能包括对事物管理和数据保护功能。
数据控制功能包括事物管理功能和数据保护功能。即: 数据的安全性、完整性、事务控制、并发控制和恢复功能。
授权机制:通过超级用户DBA进行授权
GRANT:权力授予
GRANT 权力 [,权力 ] … [ ON 对象类型 对象名 ]
TO 用户名 [,用户名] …
[ WITH GRANT OPTION ];
举例:
GRANT DELETE
ON TABLE EMP
TO User1
被授权用户可以将权限再授权给其他用户,但是不允许循环授权。
WITH GRANT OPTION 语句
用这条语句指定权限可以在被赋予,没有指定就不可以传播
GRANT INSERT
ON TABLE SC
TO U5
WITH GRANT OPTION
REVOKE:权力收回
REVOKE 权力 [,权力 ] … [ ON 对象类型 对象名 ]
FROM 用户名 [,用户名] …;
举例:
REVOKE DELETE
ON TABLE EMP
FROM User1
CASCADE语句
对于授权的时候使用了WITH GRANT OPTION语句的授权,回收的时候要使用CASCADE语句。
意思是说将你的权限收回,同时你给别人的权限也收回。
第3章
1 .什么是基本表?什么是视图?两者的区别和联系是什么?
答
基本表是本身独立存在的表,在 SQL 中一个关系就对应一个表。视图是从一个或几个基本表导出的表。视图本身不独立存储在数据库中,是一个虚表。即数据库中只存放视图的定义而不存放视图对应的数据,这些数据仍存放在导出视图的基本表中。视图在概念上与基本表等同,用户可以如同基本表那样使用视图,可以在视图上再定义视图。
2 .试述视图的优点。
答
( l )视图能够简化用户的操作; ( 2 )视图使用户能以多种角度看待同一数据; ( 3 )视图对重构数据库提供了一定程度的逻辑独立性; ( 4 )视图能够对机密数据提供安全保护。
3 .所有的视图是否都可以更新?为什么?
答:
不是。视图是不实际存储数据的虚表,因此对视图的更新,最终要转换为对基本表的更新。因为有些视图的更新不能惟一有意义地转换成对相应基本表的更新,所以,并不是所有的视图都是可更新的.
4 .哪类视图是可以更新的?哪类视图是不可更新的?
答:一般而言,单表、原始属性构成的视图可以更新(可转换成对基本表的操作)。对视图的更新不能唯一地有意义地转换成对相应基本表的更新时,不能更新视图。一般当视图由两个以上的基本表导出,或者视图的字段来自字段表达式或常数,或者视图包含GROUP BY,DISTINCT、聚集函数和嵌套查询时,该视图是不可以更新的。
\5. SQL 一般包括哪些操作?
答:定义和修改删除关系模式、定义和删除视图,插入数据,建立数据库
对数据库中的数据进行查询和更新
数据库的重构和维护
数据库安全性、完整性控制及事务控制
嵌入式SQL和动态SQL的定义
\6. 解释相关子查询和不相关子查询
答:在嵌套查询中,如果子查询的查询条件不依赖于父查询,称为不相关子查询;如果子查询的查询条件依赖于父查询,称为相关子查询